I follow over sixty one hundred and twenty blogs and feeds, split between two different readers: Planet Venus for regular checking with my browser during the day (this is the same system behind Planet Code4Lib) and Elfeed in Emacs at home. My planet has frequently-updated feeds, things I don’t want to miss, and shorter posts; Elfeed I use for infrequently updated sites or sites with long complex content I may want to read later.
My planet is hosted at Pair, where I have access to a shared server, but the script kept getting killed off because it was using too much CPU time. I decided to do some analysis to figure out which sites post the most and how to best arrange feeds between the planet and Elfeed to suit my reading habits.
The Elfeed config file looks like this (in part):
(setq elfeed-feeds
'(
"https://www.miskatonic.org/feed.xml" ;; Miskatonic University Press
;; Libraries
"http://accessconference.ca/feed/"
"http://www.open-shelf.ca/feed/" ;; Open Shelf
;; Sciences
"http://profmattstrassler.com/feed/"
"http://www.macwright.org/atom.xml"
"http://blog.stephenwolfram.com/feed/atom/" ;; Stephen Wolfram
"http://www.animalcognition.org/feed/" ;; Animal Cognition
"http://around.com/feed" ;; James Gleick
;; Literature and writing
"https://feeds.feedburner.com/ivebeenreadinglately" ;; Levi Stahl
"https://picturesinpowell.com/feed/" ;; Pictures in Powell
))
The planet config (stored on my hosted service) looks like this (in part)
[http://www.wqxr.org/feeds/channels/q2-album-week]
name = Q2 Music Album of the Week
[https://ethaniverson.com/feed/]
name = Ethan Iverson
[https://mathbabe.org/feed/]
name = Cathy ONeil
[https://www.penaddict.com/blog?format=RSS]
name = Pen Addict
To pick out all of the live (not commented) feeds I use the prepare directive in this makefile (which is in ~/src/geblogging/, where I run all these commands):
all: prepare fetch
prepare:
grep -v \;\; ~/.emacs.d/setup/setup-elfeed-subscriptions.el | grep http > feedlist.txt
scp host:planet/planet-config.ini .
grep -v \# planet-config.ini | grep http | grep -v link >> feedlist.txt
rm planet-config.ini
fetch:
gebloggen.rb feedlist.txt > feeditems.csvmake prepare does the following:
- delete everything after
;;(comments; this is Lisp) in each line in the Elfeed config then pick out all the lines containinghttp, and put them in a file - download my planet config
- pick out all the lines in the planet config that don’t start with # (comments; this is an ini file), then pick out all the lines containing
http, ignore any lines mentioninglink(there is one, part of the planet config), and add them to the file - delete the downloaded planet config
feedlist.txt looks like this:
"https://www.miskatonic.org/feed.xml"
"http://accessconference.ca/feed/"
"http://www.open-shelf.ca/feed/"
"http://profmattstrassler.com/feed/"
"http://www.macwright.org/atom.xml"
"http://blog.stephenwolfram.com/feed/atom/"
"http://www.animalcognition.org/feed/"
"http://around.com/feed"
"https://feeds.feedburner.com/ivebeenreadinglately"
"https://picturesinpowell.com/feed/"
[http://www.wqxr.org/feeds/channels/q2-album-week]
[https://ethaniverson.com/feed/]
[https://mathbabe.org/feed/]
[https://www.penaddict.com/blog?format=RSS]
Next I run gebloggen.rb, which reads in that list, picks out the URL from the formatting, downloads the feed, and outputs a simple CSV. I’ll leave my commented-out debugging lines.
#!/usr/bin/env ruby
require "csv"
require "feedjira"
puts "source,feed,date"
ARGF.each do |feed_url|
source = ""
if feed_url =~ /"/
# In setup-elfeed-subscriptions.el the feeds are in quotes,
# so pick them out and ignore everything else on the line.
feed_url = feed_url.match(/"(.*)"/)[1]
source = "E"
end
if feed_url =~ /\[/
# In setup-elfeed-subscriptions.el the feeds are in quotes,
# so pick them out and ignore everything else on the line.
feed_url = feed_url.match(/\[(.*)\]/)[1]
source = "P"
end
# puts feed_url + " ..."
begin
feed = Feedjira::Feed.fetch_and_parse(feed_url)
# puts "Title: #{feed.title}"
feed.entries.each do |item|
puts [source, feed.url.chomp, item.last_modified.to_date.to_s].to_csv ## item.title.gsub("\n", "")
# puts item.title
end
rescue StandardError => e
STDERR.puts "ERROR: #{feed_url}: #{e}"
end
endIf I run make then both the prepare and fetch directives are run, and the CSV, feeditems.csv, is made from scratch. It takes a little while to download all the feeds, but when it’s done it looks like this:
source,feed,date
E,https://www.miskatonic.org,2017-03-16
E,https://www.miskatonic.org,2017-03-10
E,https://www.miskatonic.org,2017-03-07
E,https://www.miskatonic.org,2017-03-06
E,https://www.miskatonic.org,2017-03-06
E,https://www.miskatonic.org,2017-03-02
E,https://www.miskatonic.org,2017-02-27
E,https://www.miskatonic.org,2017-02-27
E,https://www.miskatonic.org,2017-02-24
E,https://www.miskatonic.org,2017-02-21
E,https://www.miskatonic.org,2017-02-16
E,https://www.miskatonic.org,2017-02-10
E,https://www.miskatonic.org,2017-02-09
E,https://www.miskatonic.org,2017-02-08
E,https://www.miskatonic.org,2017-01-27
E,https://www.miskatonic.org,2017-01-26
E,https://www.miskatonic.org,2017-01-22
E,https://www.miskatonic.org,2017-01-20
E,https://www.miskatonic.org,2017-01-17
E,https://www.miskatonic.org,2017-01-10
E,http://accessconference.ca,2017-03-01
E,http://accessconference.ca,2017-02-28
E,http://accessconference.ca,2016-10-26
A source of E means Emacs (or Elfeed), and P means Planet.
This file is easy to load up into R for some analysis.
library(dplyr)
library(ggplot2)
library(lubridate)
library(readr)
library(tidyr)
setwd("~/src/geblogging")
items <- read_csv("feeditems.csv")With the data loaded into a data frame, it’s easy to parse in a few ways. First, posts by date.
items %>% filter(date >= Sys.Date() - months(6)) %>% group_by(date) %>% summarise(count = n()) %>% ggplot(aes(x = date, y = count)) + geom_bar(stat = "identity") + labs(title = "Dates of posts in last six months", x = "", y = "")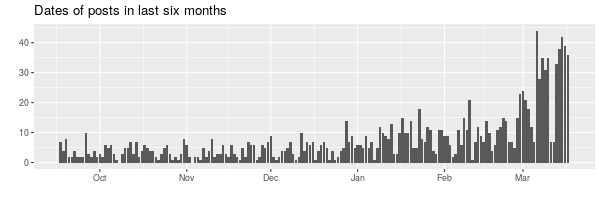
Next, items per feed.
items %>% filter(date >= Sys.Date() - months(6)) %>% group_by(feed) %>% summarise(count = n()) %>% ggplot(aes(count)) + geom_bar() + labs(title = "Items per feed in last six months", x = "", y = "")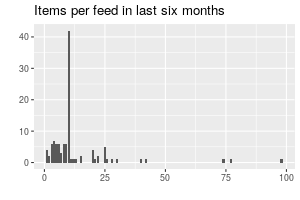
That spike there is 10: a lot of RSS and Atom feeds show the most recent ten posts. The outlier there at 98 is British music magazine The Wire.
A table listing items per feed is easy (in all these tables I only show a few example lines):
items %>% filter(date >= Sys.Date() - months(6)) %>% group_by(source, feed) %>% summarise(count = n()) %>% arrange(source, desc(count))| source | feed | count |
|--------+-------------------------------------+-------|
| E | https://www.miskatonic.org | 20 |
| E | http://www.open-shelf.ca | 10 |
| E | http://accessconference.ca | 3 |
| P | https://www.penaddict.com/ | 20 |
| P | https://ethaniverson.com | 10 |
| P | https://mathbabe.org | 10 |
This lists the feeds that have not posted in the last six months, and gives the date of the most recent post:
items %>% group_by(source, feed) %>% mutate(latest = max(date)) %>% ungroup %>% distinct(source, feed, latest) %>% filter(latest <= Sys.Date() - months(6)) %>% arrange(source, latest)| source | feed | latest |
|--------+---------------------------------------+------------|
| E | https://praxismusic.wordpress.com | 2016-01-04 |
| E | https://blogs.princeton.edu/librarian | 2016-03-24 |
| E | https://www.zotero.org/blog | 2016-04-13 |
Frequency of posts is interesting. This figures out the number of days between posts in the feed as it is. 1 means about one post per day, 34 means on average less than one post per month.
items %>% filter(date >= Sys.Date() - months(6)) %>% group_by(source, feed) %>% mutate(date_range = max(date) - min(date)) %>% group_by(source, feed, date_range) %>% summarise(count = n()) %>% mutate(frequency = round(date_range / count), 1) %>% select(source, feed, frequency) %>% arrange(source, desc(frequency))| source | feed | frequency |
|--------+----------------------------------------+-----------|
| E | http://accessconference.ca | 42 |
| E | http://www.animalcognition.org | 34 |
| P | http://www.thewire.co.uk/home/ | 1 |
| P | https://ethaniverson.com | 1 |
| P | https://www.penaddict.com/ | 1 |
The first thing all this analysis helped me do was identify blogs that I wasn’t very interested in and that also didn’t post much. Cleaning those out was a great first step. Then looking at these tables told me what I needed to know to shuffle around where I read the different feeds, and now everything is working pretty well. I’ll keep tweaking as needed.