Thanks to a combination of Access excitement, a talk by Dan Scott, a talk by Mita Williams, and wanting to learn more, I added schema.org and COinS metadata to this site. It validates, though I’m not sure if the semantic structure is correct. Here’s what I’ve got so far.
My Jekyll setup
I build this site with Jekyll. It uses static HTML templates in which you can place content as needed or do a little bit of simple scripting (inside double braces, which here I’ve spaced out: { { something } }). My main template is _layouts/miskatonic.html, which (leaving out the side, the footer, CSS and much else) looks like this:
<!DOCTYPE html>
<html itemscope itemtype="http://schema.org/CreativeWork">
<head>
<meta charset="utf-8">
<meta name="referrer" content="origin-when-cross-origin" />
<title>{ {page.title} } | { { site.name } }</title>
<meta itemprop="creator" content="William Denton">
<meta itemprop="name" content="Miskatonic University Press">
<link rel="icon" type="image/x-icon" href="/images/favicon.ico">
<link rel="alternate" type="application/rss+xml" title="Miskatonic University Press RSS" href="https://www.miskatonic.org/feed/all.xml" />
</head>
<body>
<article>
{ { content } }
</article>
<aside></aside>
</body>
</html>It declares that the web site is a CreativeWork, what its name is, and who owns it.
I have two types of pages: posts and pages. Posts are blog posts like this, and pages are things like Fictional Footnotes and Indexes.
My page template, _layouts/page.html, sets out that the page is, in the schema.org sense, an Article:
---
layout: miskatonic
---
<div itemscope itemtype="https://schema.org/Article">
{ % include coins.html % }
<meta itemprop="creator" content="William Denton">
<meta itemprop="license" content="https://creativecommons.org/licenses/by-sa/4.0/">
<meta itemprop="name" content="{ { page.title } }">
<meta itemprop="headline" content="{ { page.title } }">
{ % if page.description % }
<meta itemprop="description" content="{ { page.description } }">
{ % endif % }
<img itemprop="image" src="/images/dentograph-400px-400px.png" alt="" style="display: none;">
<h1>{ { page.title } }</h1>
<p>
<time itemprop="datePublished" datetime="{ { page.date | date_to_xmlschema } }">
{ { page.date | date_to_long_string } }
</time>
<span class="tags">
{ % for tag in page.tags % }
<a href="/posts/tags.html#{ { tag } }"><span itemprop="keywords">{ { tag } }</span></a>
{ % endfor % }
</span>
</p>
<div class="post" itemprop="articleBody">
{ { content } }
</div>
</div>Those meta tags declare some properties of the Article. Every Article is required to have a headline and an image, which doesn’t really suit my needs and shows the commercial nature of the system. For the headline, I just use the title of the page. For the image, I use a generic image that will repeat on every page, and what’s more I style it with CSS so it’s not visible. I may come back to this later and make it work better.
The layout: miskatonic at the top means that this content gets inserted into that layout where the { { content } } line is.
The _layouts/post.html template looks like this:
---
layout: miskatonic
---
<div itemscope itemtype="https://schema.org/BlogPosting">
{ % include coins.html % }
<meta itemprop="creator" content="William Denton">
<meta itemprop="license" content="https://creativecommons.org/licenses/by-sa/4.0/">
<h1 itemprop="name">{ { page.title } }</h1>
<p>
<time itemprop="datePublished" datetime="{ { page.date | date_to_xmlschema } }">
{ { page.date | date_to_long_string } }
</time>
<span class="tags">
{ % for tag in page.tags % }
<a href="/posts/tags.html#{ { tag } }"><span itemprop="keywords">{ { tag } }</span></a>
{ % endfor % }
</span>
</p>
<div class="post" itemprop="articleBody">
{ { content } }
</div>
</div>Every blog post is a BlogPosting. The same kind of properties are given about it as for a page, and the same image trick. I usually include images with blog posts and maybe there’s a simple way to make Jekyll find the first one and bung it in there. I don’t think I want to get into listing all the images I use in the YAML header … that’s too much work.
When I write a blog post, like this one, I start it with
---
layout: post
title: Now with schema.org and COinS structured metadata
tags: jekyll metadata
date: 2015-09-11 16:24:17 -0400
---
That defines that this is a post, so the Markdown is processed and inserted into the post layout, which is processed and put into the miskatonic layout, which is processed, and that’s turned into static HTML and dumped to disk. (Or something along those lines.)
Proper semantics?
This all validates, but I’m not sure if the semantics are correct. Google’s Structured Data Testing Tool says this about a recent blog post:
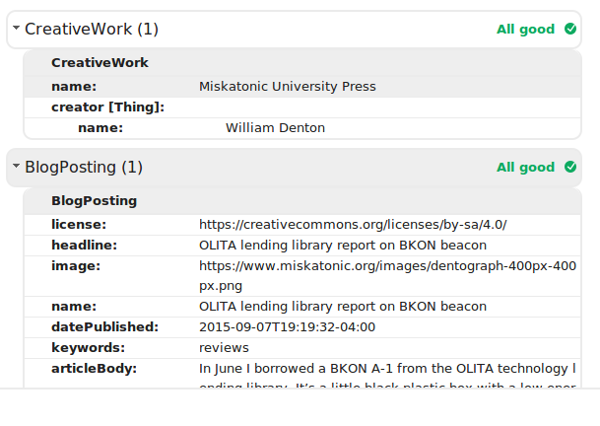
CreativeWork (my site) and the BlogPosting (the post) are at the same level. I’m not sure if the BlogPosting should be a child of the Creative Work. It is in the schema.org schema, but I don’t know if that should apply to this structure here.
Useful links
- Adding schema.org metadata to Jekyll
- Integrate the schema.org microformat with Jekyll
- Enabling rich snippets in articles
Validators:
- Google’s Structured Data Testing Tool
- Structured Data Linter
- W3C’s Nu HTML Checker
COinS
While I was at all this, I decided to add COinS metadata to everything so Zotero could make sense of it. Adapting Matthew Lincoln’s COinS for your Jekyll blog, I created _includes/coins.html, which looks like this, though if you want to use it, reformat it to remove all the newlines and spaced braces, and change the name:
<span class="Z3988" title="ctx_ver=Z39.88-2004&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Adc
&rft.title={ { page.title | cgi_escape } }
&rft.aulast=Denton&rft.aufirst=William
&rft.source={ { site.name | cgi_escape } }
&rft.date={ { page.date | date_to_xmlschema } }
&rft.type=blogPost&rft.format=text
&rft.identifier={ { site.url | cgi_escape } }{ { page.url | cgi_escape } }
&rft.language=English"></span>
I just noticed that this says the thing is a blog post, and I’m using this COinS snippet on both my pages and posts, so Zotero thinks the pages are posts, but I’ll let that ride for now. Zotero users, if you ever cite one of my pages, watch out.
COinS is over ten years old now! There must be a more modern way to do this. Or is there?
Bibliographic information in schema.org
Now that I’ve done this, search engines like Google can make better sense of the content of the site, which is nice enough, though I hardly ever use Google (I’m a DuckDuckGo man—it’s not as good, but it’s better). I would like to mark up my talks and publications so all of that citation information is machine-readable, but bib.schema.org hasn’t been formally approved yet, from what I can see. And look at all of the markup going on for something like a Chapter!
Blecch. I don’t want to type all that kind of cruft every time I want to describe a chapter or article. There are things like jekyll-scholar that would let me turn a set of BibTeX citations into HTML, but it doesn’t do microformats. Maybe that would something to hack on. Or maybe I’ll just leave it all for now and come back to it next time I feel like doing some fiddling with this site. That’s enough template hacking for one week!
Corrections welcome
If anyone who happens to read this sees any errors in what I’ve done, please let me know. I don’t really care if my headlines could be better, but if there’s something semantically wrong with what I’ve described here, I’d like to get it right.