This web site is now generated with Jekyll.
Almost five years ago I moved to Drupal from Template Toolkit. Template Toolkit (written in Perl) is just what it says on the tin: a set of tools for using template files to generate web pages and sites.
Back then I wanted a better way of managing my web site: I was editing and generating the RSS feed by hand, if I remember right, which was tedious. I wanted to be able to write more, blog more, and to experiment with CMSes as platforms for programming on the web. Drupal seemed like the best choice. At the time, WordPress seemed to be just for blogs, and I wanted more, so I ignored it. Looking back, I should have gone with WordPress. If I had, I probably wouldn’t be making the change I’m making now.
WordPress is very, very easy to upgrade and it’s possible to keep the system pretty simple. Drupal, on the other hand, is far beyond what I needed for my simple site. I can understand that Drupal can be the right platform for many sites (in the GLAM world, for example, it combines with Fedora to make Islandora) but for me it was too big, too complicated and too scary to upgrade. I used Drush for updates, and it’s a great tool, but still, every time I poked at Drupal I got nervous. Moving from version 6 to 7 or 8 didn’t look pleasant. For all those reasons, I began to think about moving away from Drupal.
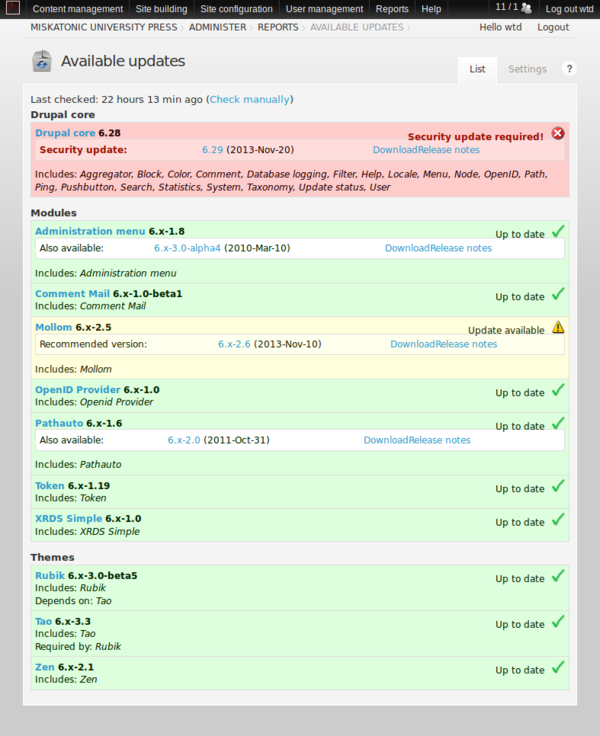
But to what? WordPress? I was surprised to find there’s no simple way to migrate from Drupal to WordPress. I guess I could have hacked something together, but I couldn’t really be bothered.
Besides, one thing that bothered me about Drupal would also bother me about WordPress: it’s not text! I like editing in Emacs and I like dealing with plain text. I don’t want to use a GUI editor in a web page. I have It’s All Text installed in Firefox, which helps, and I know there’s some XML-RPC way of talking to Drupal or WordPress that I could configure to work with Emacs, except I tried with Drupal and couldn’t get it to work. In any case, there’s still all the overhead of the CMS.
So I decided to move to Jekyll: “a simple, blog-aware, static site generator. It takes a template directory containing raw text files in various formats, runs it through [some] converters, and spits out a complete, ready-to-publish static website suitable for serving with your favorite web server.” Jekyll’s written in Ruby, now my preferred language, so it’s easy for me to hack on. When I want to move to something else, it won’t be too hard.
Here are some notes on the migration.
Getting my posts out of Drupal
The Drupal 6 migration script didn’t work out of the box, so I had to fiddle a bit, I think because of something to do with tags. This is what I ended up with. It grabs all the blog posts and dumps them out way Jekyll wants them.
#!/usr/bin/env ruby
require 'rubygems'
require 'sequel'
require 'fileutils'
require 'safe_yaml'
host = 'db.example.com'
user = 'username'
pass = 'password'
dbname = 'databasename'
prefix = ''
QUERY = "SELECT n.nid, \
n.title, \
nr.body, \
n.created, \
n.status,
u.dst \
FROM node_revisions AS nr, node AS n, url_alias as u \
WHERE (n.type = 'blog' OR n.type = 'story') \
AND n.vid = nr.vid \
AND u.src = CONCAT('node/', n.nid)
GROUP BY n.nid"
db = Sequel.mysql(dbname, :user => user, :password => pass, :host => host, :encoding => 'utf8')
if prefix != ''
QUERY[" node "] = " " + prefix + "node "
QUERY[" node_revisions "] = " " + prefix + "node_revisions "
end
FileUtils.mkdir_p "_posts"
FileUtils.mkdir_p "_drafts"
results = db[QUERY]
STDERR.puts "Posts found: #{results.count}"
results.each do |post|
# Get required fields and construct Jekyll compatible name
node_id = post[:nid]
title = post[:title]
content = post[:body].gsub(/\r/, '')
created = post[:created]
time = Time.at(created)
is_published = post[:status] == 1
STDERR.puts "#{time}: #{title}"
dir = is_published ? "_posts" : "_drafts"
slug = title.strip.downcase.gsub(/(&|&)/, ' and ').gsub(/[\s\.\/\\]/, '-').gsub(/[^\w-]/, '').gsub(/[-_]{2,}/, '-').gsub(/^[-_]/, '').gsub(/[-_]$/, '')
slug = slug[0..110] # Ran into errors about overly long filenames with truncating like this
name = time.strftime("%Y-%m-%d-") + slug + '.md'
permalink = post[:dst]
# Get the relevant fields as a hash, delete empty fields and convert
# to YAML for the header
data = {
'layout' => 'post',
'title' => title.to_s,
'created' => created,
'permalink' => permalink
}.delete_if { |k,v| v.nil? || v == ''}.each_pair {
|k,v| ((v.is_a? String) ? v.force_encoding("UTF-8") : v)
}.to_yaml
# Write out the data and content to file
File.open("#{dir}/#{name}", "w") do |f|
f.puts data
f.puts "---"
f.puts content
end
endGetting my pages out of Drupal
I did something similar to get pages out of Drupal. I had about 30, all with custom URLs. Where /about worked in Drupal, here I turn it into /about/index.html.
#!/usr/bin/env ruby
require 'rubygems'
require 'sequel'
require 'fileutils'
require 'safe_yaml'
host = 'db.example.com'
user = 'username'
pass = 'password'
dbname = 'databasename'
prefix = ''
QUERY = "SELECT n.nid, \
n.title, \
nr.body, \
n.created, \
n.status,
u.dst \
FROM node_revisions AS nr, node AS n, url_alias as u \
WHERE (n.type = 'page') \
AND n.vid = nr.vid \
AND u.src = CONCAT('node/', n.nid)
GROUP BY n.nid"
db = Sequel.mysql(dbname, :user => user, :password => pass, :host => host, :encoding => 'utf8')
if prefix != ''
QUERY[" node "] = " " + prefix + "node "
QUERY[" node_revisions "] = " " + prefix + "node_revisions "
end
results = db[QUERY]
STDERR.puts "Pages found: #{results.count}"
results.each do |page|
# Get required fields and construct Jekyll compatible name
# node_id = page[:nid]
title = page[:title]
content = page[:body].gsub(/\r/, '')
permalink = page[:dst]
unless permalink.match(/.html$/)
# puts "#{permalink} does not end in html!"
permalink = permalink + "/index.html"
end
created = page[:created]
time = Time.at(created)
# is_published = page[:status] == 1 # Assume everything is published
STDERR.puts "#{time}: #{title} (#{permalink})"
# Get the relevant fields as a hash, delete empty fields and convert
# to YAML for the header
data = {
'layout' => 'miskatonic',
'title' => title.to_s,
'date' => time
}.delete_if { |k,v| v.nil? || v == ''}.each_pair {
|k,v| ((v.is_a? String) ? v.force_encoding("UTF-8") : v)
}.to_yaml
# Write out the data and content to file
dirname = File.dirname(permalink)
unless File.directory?dirname
puts "Creating #{dirname}"
FileUtils.mkdir_p(dirname)
end
File.open(permalink, "w") do |f|
f.puts data
f.puts "---"
f.puts "<h1>#{title.to_s}</h1>\n"
f.puts content
end
endCleaning up HTML
About one in ten posts had bad HTML, which made the Markdown converter choke. I kept running this in the _posts directory to find the bad pages, then I’d clean them up in Drupal and reimport.
#!/bin/sh
for I in *.md; do
echo $I
maruku -o foo.html $I
doneA lot of the errors came from video inclusions like this:
<iframe src="http://archive.org/embed/Code4libWilliamDenton"
width="640" height="480" frameborder="0" webkitallowfullscreen="true"
mozallowfullscreen="true" allowfullscreen></iframe>I had to take out the “allowfullscreen” attribute, as explained here.
Other errors came from unescaped ampersands in Org output and a scattering of unclosed p and li tags.
The look
I used Initializr to generate a template for the site. HTML5, finally! I fiddled the CSS a bit. It needs a bit more work, I know, but tweaking things here is a dream compared to Drupal or WordPress. Drupal had 25 CSS files in play! Here there are three, but I only touch one.
Pagination
Jekyll uses Liquid for embedding bits of code in pages. Including Liquid examples in Jekyll without them getting processed seems to be a bit of a pain, so I won’t include pagination examples here. Mostly I tweaked what’s in the documentation.
Timestamps on files are important!
One bad thing about Jekyll is that it doesn’t preserve timestamps on files. Because it puts the pages together from templates each time you add or edit something and refresh the site, each file is created fresh and so appears new, even if nothing about it actually changed. I can live with that, but what bugged me was that binaries and other files that didn’t use the templates were also copied over without preserving the timestamps. In the /images/ directory, for example, every time the site was refreshed the images would be copied over and get a new timestamp.
That is wrong!
To work around it, this site is actually a melding of “dynamic” and static content. The dynamic is generated by Jekyll, and the static are images, multimedia, data and other files, which I keep in different directories. Here’s how it works.
This is my Jekyll configuration file, _config.yml:
name: Miskatonic University Press
description: William Denton
markdown: redcarpet
pygments: true
permalink: /:year/:month/:day/:title
TZ: America/Toronto
encoding: UTF-8
paginate: 5
paginate_path: posts/page:num
include: ['.htaccess', 'js', 'css']
exclude: []
url: http://www.miskatonic.org
rss_path: /
rss_name: feed
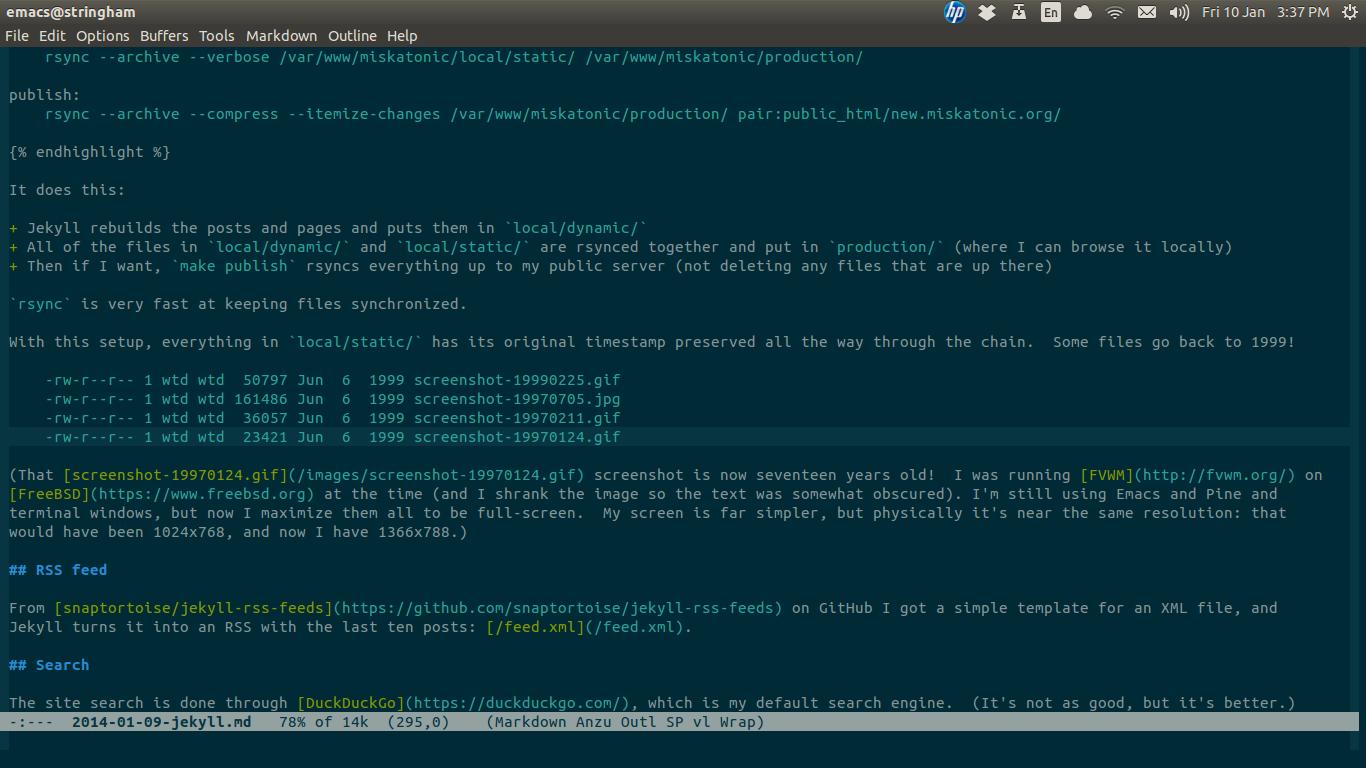
destination: /var/www/miskatonic/local/dynamic/Over in /var/www/miskatonic/ things are laid out like this:
/var/www/miskatonic/
local/dynamic/
local/static/files/
local/static/images/
production/
When I want to update the site, I run make with this Makefile:
all: build combine
build:
jekyll build
combine:
rsync --archive --verbose /var/www/miskatonic/local/dynamic/ /var/www/miskatonic/production/
rsync --archive --verbose /var/www/miskatonic/local/static/ /var/www/miskatonic/production/
publish:
rsync --archive --compress --itemize-changes /var/www/miskatonic/production/ pair:public_html/miskatonic.org/It does this:
- Jekyll rebuilds the posts and pages and puts them in
local/dynamic/ - All of the files in
local/dynamic/andlocal/static/are rsynced together and put inproduction/(where I can browse it locally) - Then if I want,
make publishrsyncs everything up to my public server (not deleting any files that are up there)
rsync is very fast at keeping files synchronized.
With this setup, everything in local/static/ has its original timestamp preserved all the way through the chain. Some files go back to 1999!
-rw-r--r-- 1 wtd wtd 50797 Jun 6 1999 screenshot-19990225.gif
-rw-r--r-- 1 wtd wtd 161486 Jun 6 1999 screenshot-19970705.jpg
-rw-r--r-- 1 wtd wtd 36057 Jun 6 1999 screenshot-19970211.gif
-rw-r--r-- 1 wtd wtd 23421 Jun 6 1999 screenshot-19970124.gif
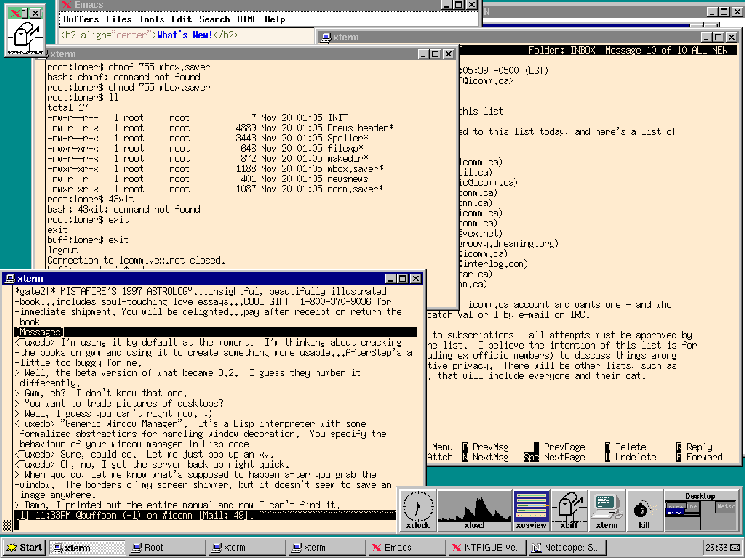
(That screenshot-19970124.gif screenshot is now seventeen years old! I was running FVWM on FreeBSD at the time (and I shrank the image so the text was somewhat obscured). I’m still using Emacs and Pine and terminal windows, but now I maximize them all to be full-screen. My screen is far simpler, but physically it’s near the same resolution: that would have been 1024x768, and now I have 1366x788.)
{kind=link}
RSS feed
From snaptortoise/jekyll-rss-feeds on GitHub I got a simple template for an XML file, and Jekyll turns it into an RSS with the last ten posts: /feed.xml.
Search
The site search is done through DuckDuckGo, which is my default search engine. (It’s not as good, but it’s better.)
Good and bad about Jekyll
On the good side, I love being able to write in Markdown to a local file and then use the command line to update the site and push it live. I’ll look into how I can integrate it with Org mode, too. The syntax highlighting with Pygments will be nice. And no more worries about upgrading! Anything that happens with Jekyll will be easy to manage, I’m sure, and if something comes up I don’t like, I can just stick with an older version—-there can be no security implications, because it’s just a static site.
One bad thing is that there’s no way to do comments. I could use an external commenting system, but in the five years I was on Drupal, I didn’t get many comments. I appreciated all the ones I did (thanks to everyone who left a comment!) but unless and until I add some way of doing comments here, people will just have to email me or catch me on Twitter (@wdenton).
To do
- Some redirections are in place that I’d rather have as rewrites.
- Add an XML sitemap.
- Get some visitor analysis working, either by analyzing the logs or with Piwik.
- Use Emacs’s time-stamping to my benefit.
Conclusion
I think all of the content is moved over and everything is working. If not, let me know.