I've been thinking about how I might change how I do backups. I set up an account at Amazon Web Services so I could use S3, their online storage system. Since I already have an Amazon account it was trivial to get started.
I'm doing all this on my new Ubuntu machine. Along the way I had to install a bunch of new libraries and packages, and I didn't keep track. I'll mention what I remember. Sorry about that. Oh, and in the examples below I sometimes add some comments with a #. For my examples I use test-file.mp3 and file.jpg, two copies of the same file, which is why they have identical byte sizes.
s3cmd
s3cmd is part of s3tools. I installed it from the s3cmd package and then ran s3cmd --configure to set it up. I didn't tell it to do encryption and it failed a test when I told it to use HTTPS, so I turned that off. It made a .s3cfg file and then I was all set:
$ s3cmd mb s3://wdenton.example # Two Python warnings skipped in all these quotes Bucket 'wdenton.example' created $ s3cmd put test-file.mp3 s3://wdenton.example/ File 'test-file.mp3' stored as s3://wdenton.example/test-file.mp3 (1613952 bytes in 23.6 seconds, 66.84 kB/s) [1 of 1] $ s3cmd ls 2009-06-28 01:06 s3://wdenton.example $ s3cmd ls s3://wdenton.example/ Bucket 's3://wdenton.example': 2009-06-28 01:10 1613952 s3://wdenton.example/test-file.mp3 # You can make folders, except they're fake $ s3cmd put test-file.mp3 s3://wdenton.example/dir/test-file.mp3 File 'test-file.mp3' stored as s3://wdenton.example/dir/test-file.mp3 (1613952 bytes in 19.0 seconds, 82.98 kB/s) [1 of 1] $ s3cmd ls s3://wdenton.example/ Bucket 's3://wdenton.example': 2009-06-28 02:31 1613952 s3://wdenton.example/dir/test-file.mp3 2009-06-28 01:10 1613952 s3://wdenton.example/test-file.mp3
s3fs
The s3fs project has a page called FuseOverAmazon that explains how to mount an S3 bucket as a file system. (Fuse stands for Filesystem in Userspace.) To get this working I think I installed the libfuse2, libfuse-dev, and fuse-utils packages (or at least they're installed now and everything works), and g++ so I had a C++ compiler. You have to compile this thing by hand, but just run make and move the binary somewhere useful.
There are differences between how s3fs and other things handle "directories" in S3 buckets. In another test where I used s3cmd sync I couldn't see any of the files with s3fs, but in this example I seem to have made it work, sort of.
$ s3fs wdenton.example -o accessKeyId=my_access_key -o secretAccessKey=my_secret_key mnt $ cd mnt $ ls -l # Notice that it doesn't see the dir "directory" I made above total 1577 ---------- 1 root root 1613952 2009-06-27 21:10 test-file.mp3 $ cp ~/file.jpg . $ ls -l total 3153 -rw-r--r-- 1 buff buff 1613952 2009-06-27 22:50 file.jpg ---------- 1 root root 1613952 2009-06-27 21:10 test-file.mp3 $ mkdir dir $ mv file.jpg dir/ $ ls -l total 1577 drwxr-xr-x 1 buff buff 0 2009-06-27 22:51 dir ---------- 1 root root 1613952 2009-06-27 21:10 test-file.mp3 $ cd dir $ ls -l # But after I made dir here, it saw the file I'd put there earlier total 3153 -rw-r--r-- 1 buff buff 1613952 2009-06-27 22:50 file.jpg ---------- 1 root root 1613952 2009-06-27 22:31 test-file.mp3 $ cd $ fusermount -u mnt/
How to s3fs on EC2 Ubuntu has some helpful information.
Duplicity
duplicity gives "encrypted bandwidth-efficient backup using the rsync algorithm." I used rsync and rdiff-backup to synchronize files, and this is the same kind of thing. I installed it from the package.
This environment variable stuff isn't documented in the man page, but it's explained here: Duplicity + Amazon S3 = incremental encrypted remote backup.
$ mkdir test $ mv file.jpg test-file.mp3 test/ $ export AWS_ACCESS_KEY_ID=my_access_key $ export AWS_SECRET_ACCESS_KEY=my_secret_key $ duplicity test/ s3+http://wdenton.example/test/ GnuPG passphrase: [I enter a phrase] No signatures found, switching to full backup. Retype passphrase to confirm: [I reenter the phrase] --------------[ Backup Statistics ]-------------- StartTime 1246158681.12 (Sat Jun 27 23:11:21 2009) EndTime 1246158681.53 (Sat Jun 27 23:11:21 2009) ElapsedTime 0.41 (0.41 seconds) SourceFiles 0 SourceFileSize 3232000 (3.08 MB) NewFiles 0 NewFileSize 0 (0 bytes) DeletedFiles 0 ChangedFiles 0 ChangedFileSize 0 (0 bytes) ChangedDeltaSize 0 (0 bytes) DeltaEntries 0 RawDeltaSize 3227904 (3.08 MB) TotalDestinationSizeChange 2956111 (2.82 MB) Errors 0 ------------------------------------------------- # Let's see what's in the test/ directory up there $ s3cmd ls s3://wdenton.example/test/ Bucket 's3://wdenton.example': 2009-06-28 03:12 76249 s3://wdenton.example/test/duplicity-full-signatures.2009-06-27T23:11:12-04:00.sigtar.gpg 2009-06-28 03:12 189 s3://wdenton.example/test/duplicity-full.2009-06-27T23:11:12-04:00.manifest.gpg 2009-06-28 03:11 2955922 s3://wdenton.example/test/duplicity-full.2009-06-27T23:11:12-04:00.vol1.difftar.gpg # Now let's do a test restore $ cd /tmp $ duplicity s3+http://wdenton.example/test/ test/ GnuPG passphrase: [I enter the phrase] $ cd test/ $ ll total 3168 -rw-r--r-- 1 buff buff 1613952 2009-06-27 22:28 file.jpg -rw-r--r-- 1 buff buff 1613952 2009-06-27 21:10 test-file.mp3
S3Fox Organizer
S3Fox is the simplest way to get into your S3 space: it's a Firefox extension and lets you drag and drop files. Here's a screenshot:
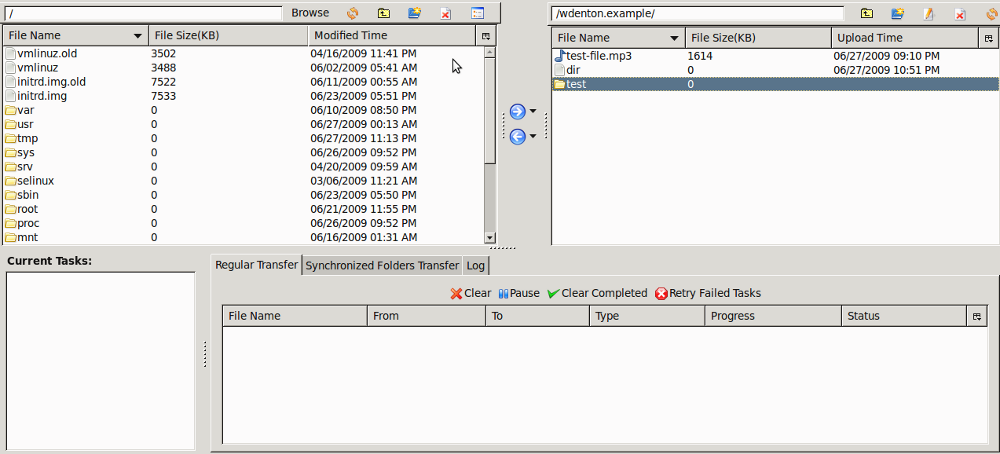
Something about the dir/ directory I made with s3fs doesn't work here, but the test/ directory I made with duplicity does. s3fs doesn't see the test/ directory. It seems like if you go with s3fs you pretty much have to stick with it, but these other tools are work nicely together.
Conclusion
If I do start using this for backups, I'll use Duplicity and do manual stuff with s3cmd and S3Fox.